Availability Back
- Availability(可用性)注重的是一個系統的錯誤以及其後果
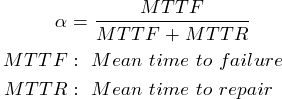
- 正常維護時間並不算入故障時間
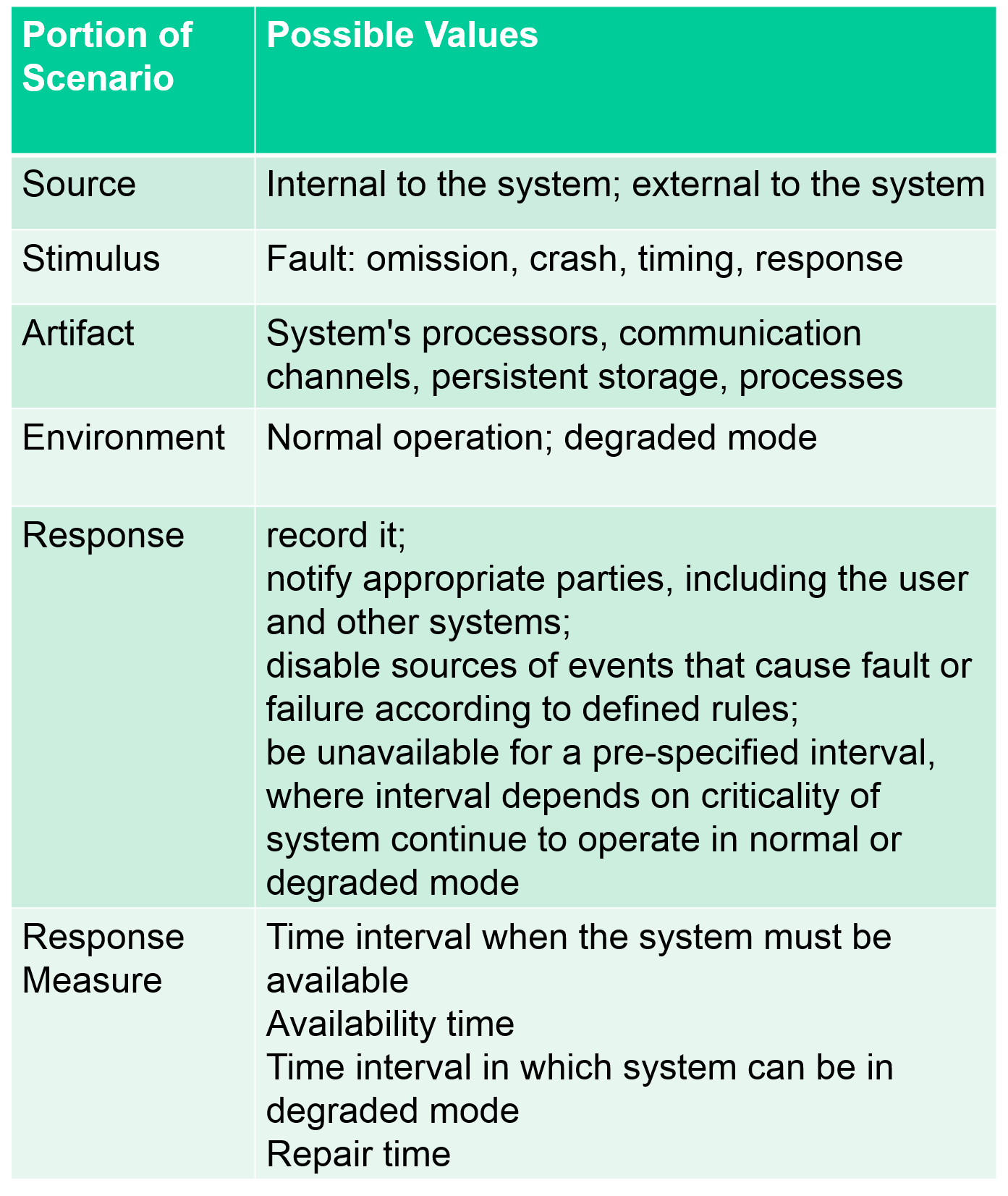
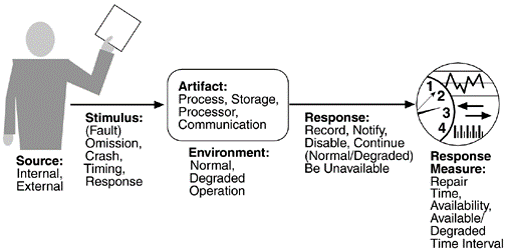
- 故障
- Omission: 無反應
- Crash: 反復無反應
- Timing: 反應時間不穩定
- Response: 反應錯
Scenarios(場景)
Tatics(策略)
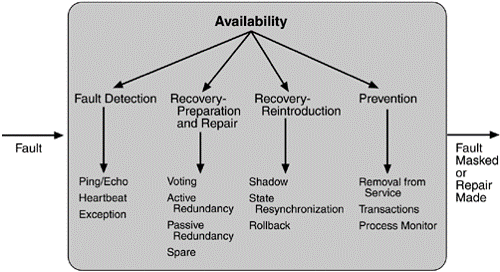
1. Fault Detection(錯誤檢測)
- Ping/Echo: 監控部分->關鍵部分
- Heartbeat: 關鍵部分->監控部分, 週期性發送脈搏信息給監控部分
- Exception: 異常處理
2. Fault Recovery(錯誤修復)
Preparation and Repair
- Voting: 通過投票, 多數票決定系統正確的狀態
- Active Redundancy: 主動備份系統, 缺點在於備份端存在硬件損耗問題.
- Passive Redundancy: 被動備份系統, 缺點在於無法完全恢復出錯前的狀態, 可通過日誌來解決.
- Spare: RAID存儲
Reintroduction
- Shadow Operation: 上線前先進行測試
- State Resynchronization: 狀態重新進行恢復
- Checkpoint/rollback: 設置檢查點以便回滾到某一狀態
3. Fault Prevention(錯誤防止)
- Removal from Service: 惹不起躲得起, 避開攻擊
- Transaction: 通過事務來防止錯誤產生
- Process Monitor: 通過任務管理器來重新運行進程